Common Computation
The common computation logic for a group extracts logic from queries in the group. Then it combines that logic into a valid SQL query that generates the same output as all the different queries in the group. This consolidates logic from many queries into a single, reusable one you can materialize in your warehouse.
You can access the common computation using the "Actions" button in the top right of an audit group's detail page. You can also download a CSV that rewrites all of the original queries in the group to use the common computation table.
Once you materialize the common computation table in your warehouse, you can use the rewritten queries instead of the original queries to save time and compute resources.
Learn More
For an example of how to realize savings using common computation, see our case study 💰
Prerequisites for Materializing Tables
- Must be able to refresh tables on a schedule to keep the underlying data up-to-date
- Must be able to backfill tables when necessary e.g. if a scheduled run is missed
- (Optional) Large tables should be partitioned to make them easier to work with
Options for Materializing Tables
There are multiple ways to materialize tables in your warehouse. At a high level, we will break them into different sections:
- (Simple) using features of your data warehouse. If your common computation query is simple, requires no customization of compute resources, and can be handled by the data warehouse, then these options are a great starting point.
- (Advanced) using your orchestration tool
BigQuery
If you're using BigQuery, you can use BigQuery built-in functionality to maintain a common computation table. The following shows how you can materialize a table using BigQuery UI.
You can use BigQuery's scheduled query feature to create a table based on the common computation logic:
- Go to the BigQuery UI. Open a tab to compose a query.
- Add your common computation SQL and then "Create new scheduled query." The example below uses the following SQL, but please replace this with your common computation logic:
SELECT
*
FROM `sandbox-demo-db.tpch_sf1.orders`
WHERE O_ORDERDATE = @run_date
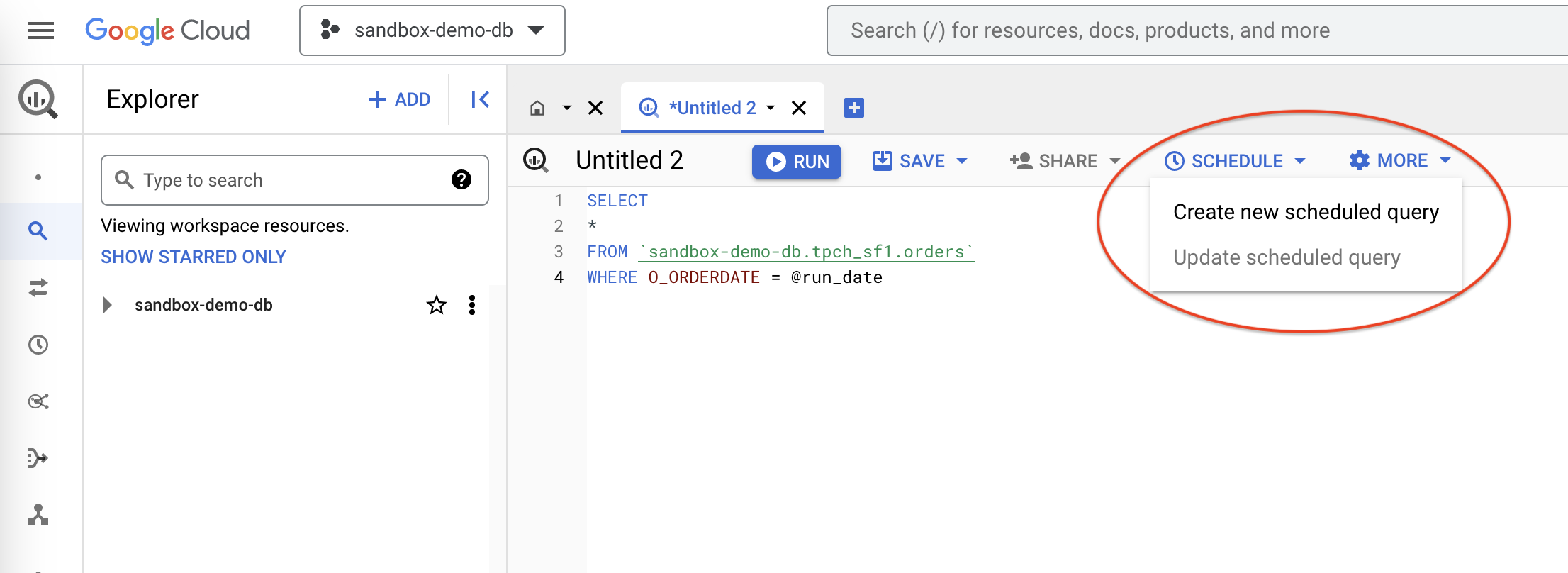
Create Schedule Query
- Schedule the query to run daily (or to run at the necessary interval to keep data fresh).
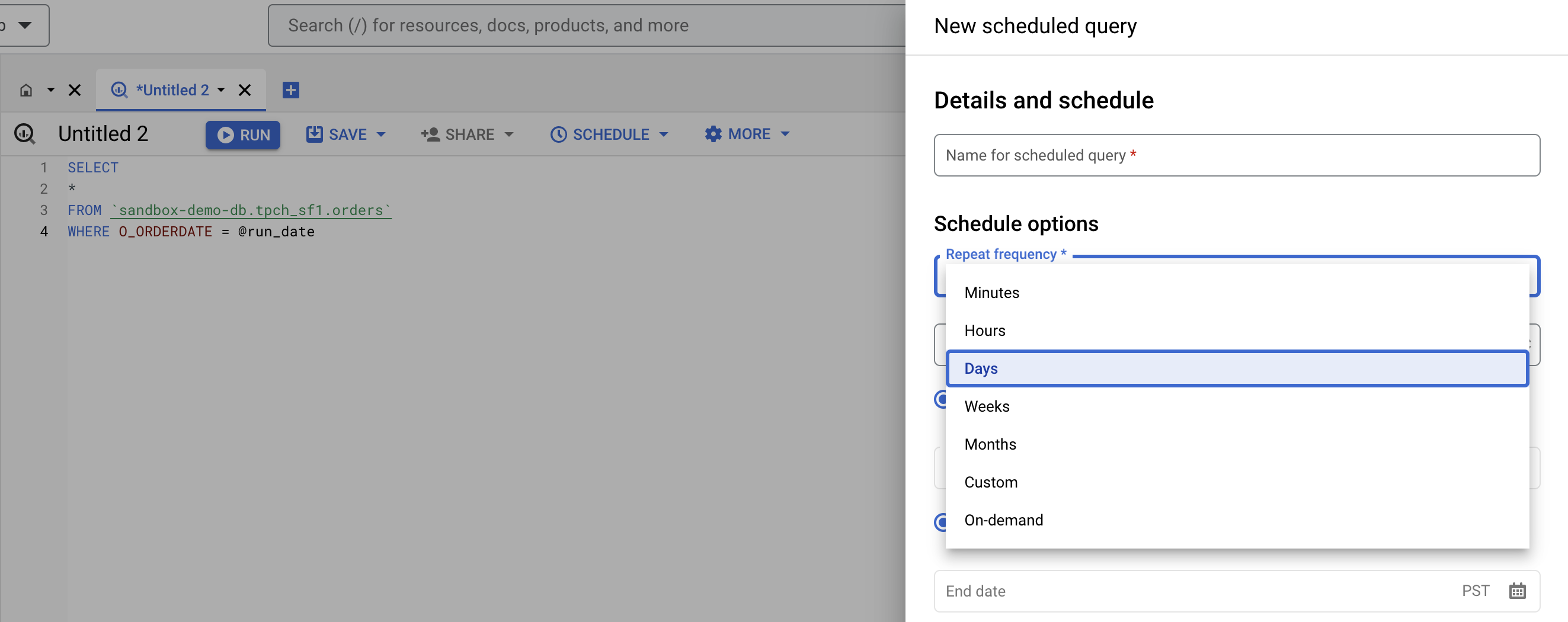
Set Schedule
- Set a destination table for the query results. This table name should be the same as in the CSV you can download for the group. For example, if the CSV has a first row with "Common SQL can be used to create a table called TABLE_NAME", then enter
TABLE_NAMEas the destination table.- For tables partitioned by date, you can specify the destination table with
TABLE_NAME${run_date}and set the write preference toWRITE_TRUNCATE(Overwrite Table).
- For tables partitioned by date, you can specify the destination table with
- Save the scheduled query 🎉
- Finally, you can schedule a backfill using the partition range:
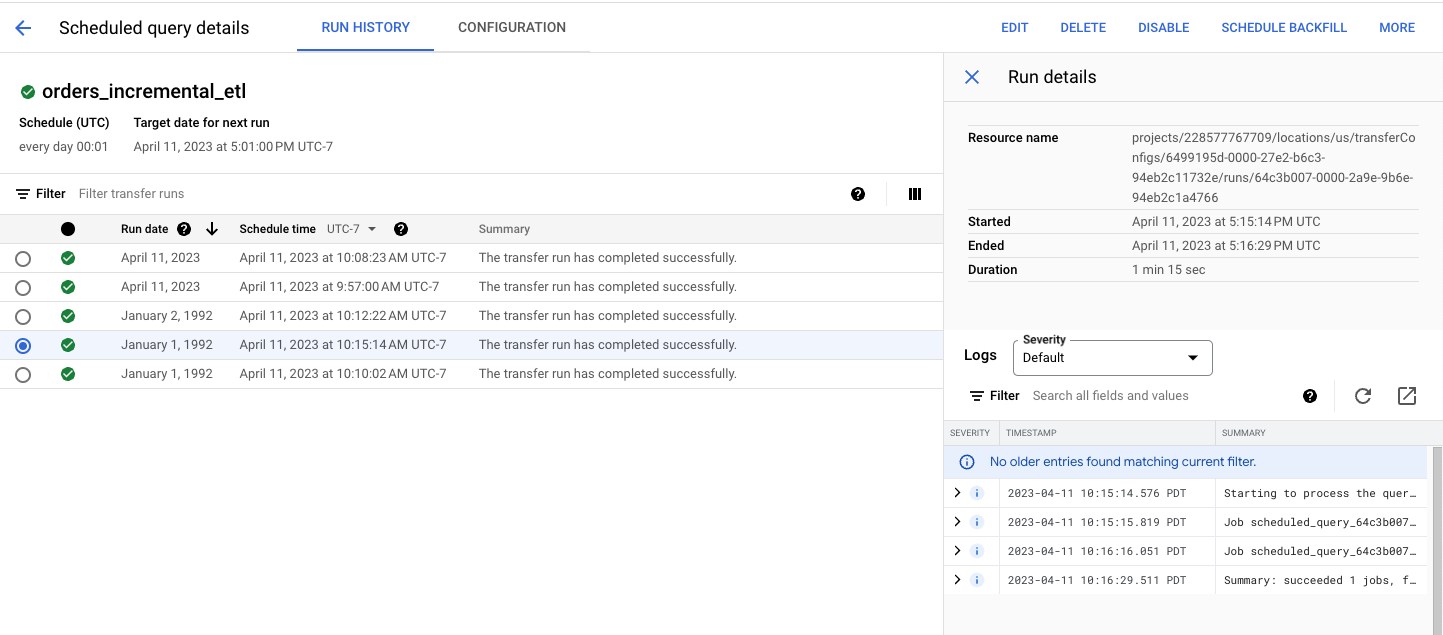
Learn More
To learn more, see BigQuery's guide to scheduling queries here.
Snowflake
The following shows how you can materialize a table using Snowflake's CREATE TASK functionality: https://docs.snowflake.com/en/sql-reference/sql/create-task#examples
Warehouse Agnostic
The following describes a general approach to how you can materialize the common computation table for any data warehouse such as Snowflake, Presto/Hive, BigQuery, etc.
To create a table based on the common computation logic and then incrementally update it:
- Create a data pipeline to run with the required schedule, i.e., daily or hourly.
- Copy your common computation SQL. Use this common computation SQL to generate the data based on the partition for each run.
- Update the destination table.
A common way to create a data pipeline is using Spark:
- Create a Spark job that writes the common computation SQL query result into parquet format.
- Load the partition into the destination table.
- Set up a scheduler such as Airflow to periodically execute the Spark job.
FAQ
- Why does a group not have common computation logic?
- Currently, we only extract specific patterns from queries. Also, certain aggregations are difficult to rewrite - for example, aggregations with DISTINCT.
- We are constantly adding more, so coverage will increase over time!
- How do I know if the common computation logic will reproduce the output from a specific original query?
- If "Covered By Common Query" is true for a query in the table, then the common computation logic will reproduce the output from the original query.
- What if I want to change the common computation query?
- At this time, you will need to create a new table and backfill all data.
Updated 7 months ago