Audits
Query Audits allow Admins to gain insight into query sets outside the Single Origin platform, and to identify consolidation opportunities in a user’s external system. Query Audits follow a similar flow to Bulk Imports, but they do not create entities within the Single Origin platform.
Navigate to the Query Audits page by selecting Manage in the navigation bar and then clicking Audits. From here, administrators can create new query audits and view a history of previously run query audits. Click on a query audit to see more details about that audit.
Prerequisites for a new Query Audit
- Queries must be in an existing collection. To create a collection, see Query Collections.
- Your personal connector must have permission to access all referenced tables
Running a Query Audit
To start a Query Audit, click the "Run Query Audit" button at the top right corner of the Audits tab: https://{tenant}.singleorigin.tech/manage?tab=audits. Give your audit a name, and then select the collection you would like to audit. Once you click Confirm, the audit will start.
The time to process a set of queries varies depending on complexity. Expect an audit of 100 SQL queries to take 1 minute.
Audit Results
View the results for a query audit by selecting the desired run in the "Audits" table. From here, you can navigate the results in Single Origin or export the results CSV (using the "Actions" button) to explore locally.
When you open the details for a query audit run, the "Processed Queries" tab has metadata for the audit, including:
- Source - The query collection that was audited.
- Queries in collection / Included in audit / Not included in audit - The number of queries (a) in the associated collection / (b) that were successfully processed for the audit / (c) that failed to be processed for the audit.
- Exact Queries - The total number of queries across all groups with Similarity =
EXACT, divided by the number of queries successfully processed.EXACTmeans that all queries in the group join the same tables in the same way
In an audit, queries in the source collection are grouped based on the tables referenced, then by dimension and metric expressions. The results of the query audit include one row per group, where every query in the group references the same common set of tables.
| Column | Description |
|---|---|
| Group Number | INTEGER - Each row should have a unique group number, starting at 0 and increasing by 1. |
| Query Count | INTEGER - The count of queries in the group. |
| Similarity | STRING - EXACT or SIMILAR. Are expressions from commonDatasets and commonFormulaCount exactly the same, or not exactly the same but similar? EXACT means that all queries in the group join the same tables in the same way. |
| Common Tables | ARRAY OF STRINGS - For the queries in the group, what are common datasets? A dataset must appear in all queries in the group to be included in common tables. |
| Longest Query | INTEGER - The longest query in the group (number of lines in original, unformatted query). |
| Common SQL | BOOLEAN - Does the group have common SQL logic or not? |
| Cost | NUMERIC - What is the total cost of running all the queries in the group? Only available when the query collection being audited is sourced from a query history table in your warehouse. If you are connected to BigQuery, then the cost is measured in billable MB. If you are connected to Snowflake, then the cost is measured in Snowflake credits. |
| Users | ARRAY OF STRINGS - What is the unique list of users writing the queries that appear in the group? |
Results CSVThe results CSV is returned in pipe form. To view in an app like Google Sheets, use a custom separator on import.
Currently, Single Origin outputs groups of queries that are EXACT matches and some metadata on the groups.
Group Results
When looking into an individual group in an audit, you can see:
- each SQL query in the group. The "Index" is the index for the query in the query collection that was audited.
- common tables referenced by queries in the group
- common formulas in the group & how frequently each formula appears
- common computation (SQL) logic for the group
For more on common computation logic, see Common Computation.
You can also generate a cost savings plan for groups with common computation logic. For more on cost savings plans, see Cost Savings Plans
Audit Insights
In addition to audit and group results, you can see audit insights on the "Insights" tab. Audit insights include:
- A cost breakdown for each group of queries.
- If you are connected to BigQuery, then the cost is measured in billable MB.
- If you are connected to Snowflake, then the cost is measured in Snowflake credits.
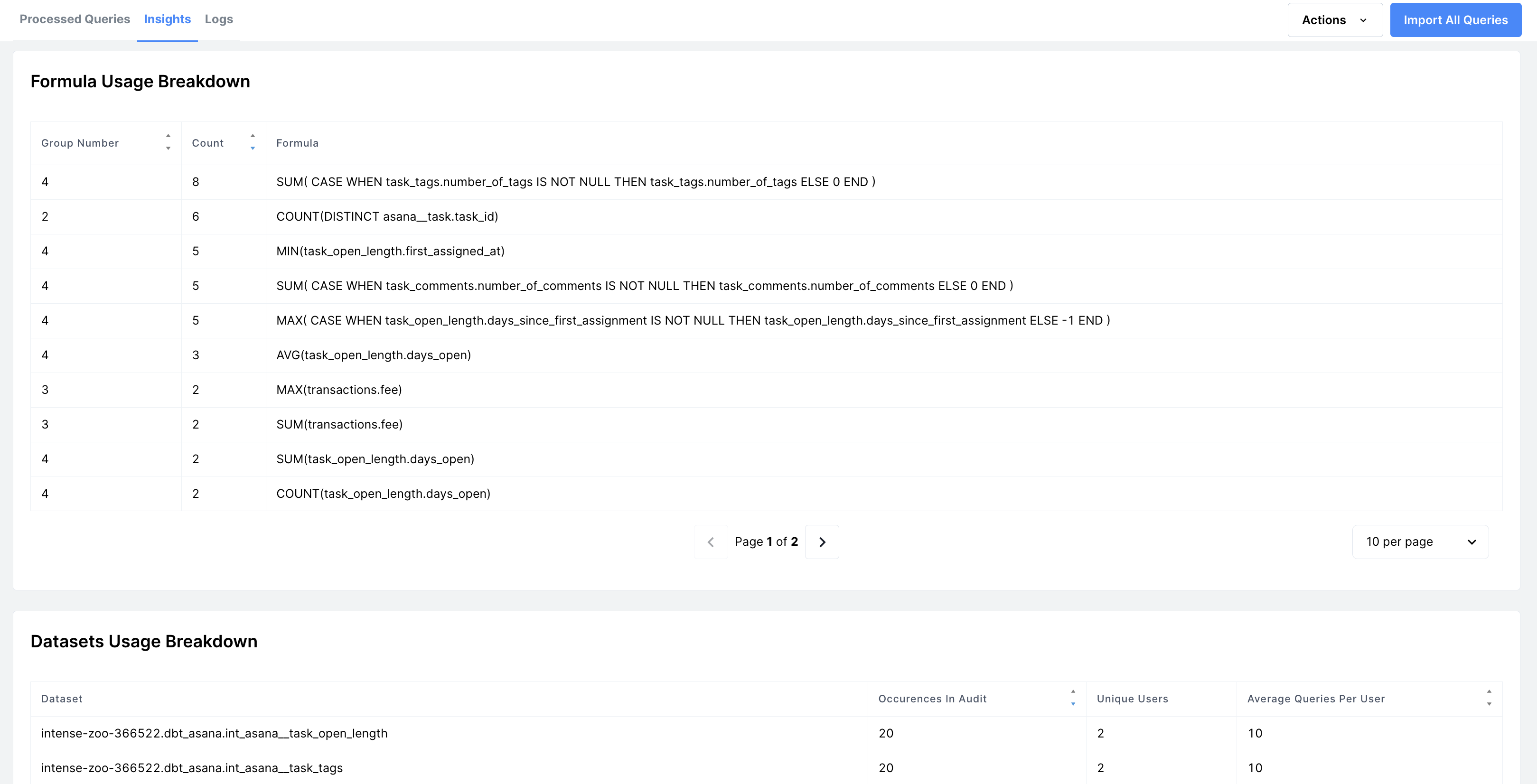
- A summary of common formulas used across the collection being audited, as well as how frequently each formula appears. This lets you know what metrics are commonly being queried.
- A summary of common datasets queried across the collection being audited, as well as how frequently each dataset is queried and how many unique users are querying the dataset. This lets you know what datasets are most popular & if the datasets are being used by multiple users.

Audit Insights
More Audit Insights
NoteNote that cost statistics are only displayed when the query collection being audited is sourced from a query history table in your warehouse. Cost statistics will not be displayed when the query collection being audited is sourced from a CSV or compliant table.
Bulk Import
After running a query audit, you can directly import queries from the underlying collection into Single Origin. To start a Bulk Import from an audit's detail page, click the "Actions" button at the top right corner of the page and then select "Import Queries."
FAQ
- Why did a query fail to process?
- There are several potential reasons:
- The SQL query is invalid.
- The SQL query is valid, but it references a table in a different project/warehouse than your Single Origin Connector. In this case, we do not have schema metadata for the table.
- Your Single Origin connector has not finished syncing. If there is a sync in process, then we may only have partial schema metadata.
- To learn more, check the "Logs" tab on an audit's details page.
- There are several potential reasons:
- Why does a query in my source not show up in the results?
- In the results table, we only display queries that are similar or exact matches to other queries in the set. If a query is unique (e.g., references a table that no other queries reference), it will not appear in the results table.
- Why do I see "No Results Found" as a result of my audit?
- This can happen for one of two reasons:
- There is no duplication between queries in your set.
- We failed to process some (or all) queries, which led to the appearance of no duplication between queries in your set.
- This can happen for one of two reasons:
- Can I combine the results of multiple query audits?
- At this time, each audit is specific to the source queries provided for that audit. You cannot combine audits from different sets of queries - you would have to provide the entire set of queries into a single audit.
Updated 3 months ago